缓解假墙伪墙攻击勒索的多种技术手段
我们知道,墙封锁一个网站有DNS污染、IP封锁、TCP Reset(TCP连接重置)等手段。而一个网站一旦被墙,一般情况下是无法直接通过301(或302)跳转到其他网站的。如果只是IP被封还好说,换IP通常能解决问题。但如果是根据域名关键字进行的TCP Reset,这时候不管怎么换IP(除非是国内IP)都无法解除封锁,当然也不可能进行301跳转(浏览器在收到HTTP服务器的301跳转Response之前TCP连接就已经被墙Reset而断开了,浏览器根本收不到HTTP服务器的任何Response)。而DNS污染的话自然更不用多说,只能换域名了,301跳转更不可能做到。然而,现在出现了很多号称可以解决域名被墙的服务,可以在网站被墙后通过301跳转到新的网站上。经过测试,还真能做到绕过墙的TCP Reset封锁,而这些服务的IP却都在海外(并非是使用了国内IP避免被墙的原因),而客户端只需要一个正常的浏览器即可(即客户端并不需要开启科学上网)。那么它们是怎么做到的呢?
要解释清楚其中的技术原理,还得回到2010年的西厢计划。很早就经常科学上网的同学们应该都对西厢计划并不陌生,它是一个只需要运行在客户端就能绕过很多封锁访问目标网站的工具,解决TCP Reset的原理是对本地的TCP/IP协议进行修改,在不伤害客户端和服务器之间的TCP连接的前提下让墙误以为TCP连接已经断开或者无法正确跟踪到TCP连接。之后出现的INTANG项目同样是这个想法的延续。
不过,不管是西厢计划还是INTANG,都是运行在客户端上的工具,理论上只在服务器上运行无法起到效果,经过测试也能看到实际和理论相符。那么有没有一种工具可以在只服务器上运行,修改TCP/IP协议从而绕过封锁的工具呢?这方面同样有团队做了研究,研究的成果就是Geneva项目,GFW Report也对其做了详细介绍。在这篇文章中,列举了6种可以绕过TCP Reset的规则,6种规则都可以在只客户端部署生效(这时候服务器并不需要运行Geneva),而前4种可以在只服务器部署生效(这时候客户端并不需要运行Geneva)。不过Geneva的官方Github中只收录了客户端的规则,文章中的服务器规则并没有被收录在Geneva的官方Github中。而且文章中的策略3只给出了客户端的规则,遗漏了服务器端的规则。经过阅读Geneva的规则介绍和策略3的描述,我已经重新还原了策略3的服务器规则,重新收录了4种服务器规则到我自己的Github Fork中。经过本地环境的模拟加上tcpdump抓包观察测试,看到还原的策略3服务器规则和文章中描述的行为一致,可以认为就是策略3本来的服务器规则。但是,在之后的真实环境的测试中发现这4种服务器策略全都失效了(不管HTTP还是HTTPS都已失效),墙依然对TCP进行了Reset。经过抓包看到服务器的行为确实和文章中描述一致,所以可以确认并非是由于Geneva没有正常工作导致的,而是墙已经为了应对这4种策略进行进化了。所以,墙并不是一成不变的,而是会进化的,那我们又该怎么办呢?
讲到这里,就不得不提另一个策略发现工具SymTCP了。虽然现有的4种策略已经失效,但并不代表我们不能发现新的策略。而SymTCP就是新策略发现工具,通过自动学习可以自动发现新的策略绕过墙的TCP Reset。之后我们就能把新的策略转换为Geneva的规则格式进行使用了。不过,这样的话我们就会陷入到和墙的无休止争斗中,不断发现新策略,而墙则不断封锁新策略。而且规则的转换也是一个麻烦事,暂时还没有工具可以自动从SymTCP的规则转换为Geneva的规则,需要人工转换。并且需要修改SymTCP使其不仅可以发现客户端规则同样也能发现服务器端规则。
那么,有没有一种一劳永逸的方法,使墙再怎么进化也无法避免这种策略的影响,而且这种策略只需要运行在服务器上,从而绕过封锁呢?在下结论之前,我们需要来研究一下一个正常的HTTP协议通讯是怎么进行的:
- 浏览器发起TCP连接,经过3步(次)握手建立和服务器的TCP连接。
- 浏览器发送HTTP Request。
- 服务器收到Request,发送HTTP Response。
而墙通常在看到浏览器发送的HTTP Request中包含关键字就会进行TCP Reset。讲到这里,聪明的同学或许已经想到了:如果服务器不等HTTP Request,而在TCP连接建立后立即发送HTTP Response,在墙进行TCP Reset之前就将Response送到浏览器进行抢答,是不是就能绕过TCP Reset了?而且还能无视之后墙的进化(因为浏览器的请求根本还没有经过墙)?说干就干,由于抢答模式不符合HTTP规范,所以常见的HTTP服务器无法实现抢答模式,所以让我们写个Python小程序来测试一下:
import socket
import threading
import time
def main():
serv_sock = socket.socket()
serv_sock.bind(('0.0.0.0', 80))
serv_sock.listen(50)
# 关闭Nagle算法,立即发送数据
serv_sock.setsockopt(socket.IPPROTO_TCP, socket.TCP_NODELAY, 1)
# 不等待,立即关闭连接
serv_sock.setsockopt(socket.SOL_SOCKET, socket.SO_LINGER, struct.pack('ii', 1, 0))
while True:
cli_sock, _ = serv_sock.accept()
try:
cli_sock.sendall(b'''HTTP/1.1 302 Moved Temporarily\r\n'''
b'''Content-Type: text/html\r\n'''
b'''Content-Length: 0\r\n'''
b'''Connection: close\r\n'''
b'''Location: https://www.microsoft.com/\r\n\r\n''')
except Exception: # 防止客户端提前关闭连接抛异常
pass
def wait_second():
time.sleep(1) # 等待1秒钟,确保数据发送完毕
cli_sock.close()
threading.Thread(target=wait_second).start()
if __name__ == '__main__':
main()
写完了来测试一下,发现依旧被TCP Reset了。那么,问题出在哪里?让我们重新回到上述HTTP协议通讯的3个步骤中的第1步——TCP的3步握手:
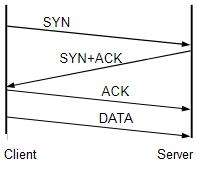
从TCP的3步握手中,我们可以看到第3步中客户端发送了ACK就已经完成了TCP连接的建立,这时候客户端并不需要再等服务器的回复就能立即发送数据。也就是说,浏览器会在发送ACK后立即发送HTTP Request,ACK和HTTP Request几乎是同时发出的。而服务器在收到浏览器的ACK后基本也就代表着已经收到了HTTP Request了,抢答失败!
那么,有没有办法让浏览器在TCP连接建立后延迟发送HTTP Request,而又不改动客户端行为呢?讲到这里,对TCP协议比较熟悉的同学或许已经想到了,那就是TCP window size。而通过调用setsockopt()就能修改TCP window size。让我们来修改一下Python小程序,把window size改为1再进行测试(TCP连接建立完成后,客户端只能发送1个字节,等待服务器的确认后才能继续发送更多的数据):
import socket
import struct
import threading
import time
def main():
serv_sock = socket.socket()
serv_sock.bind(('0.0.0.0', 80))
serv_sock.listen(50)
# 设置TCP window size为1
serv_sock.setsockopt(socket.SOL_SOCKET, socket.SO_RCVBUF, 1)
# 不等待,立即关闭连接
serv_sock.setsockopt(socket.SOL_SOCKET, socket.SO_LINGER, struct.pack('ii', 1, 0))
# 关闭Nagle算法,立即发送数据
serv_sock.setsockopt(socket.IPPROTO_TCP, socket.TCP_NODELAY, 1)
while True:
cli_sock, _ = serv_sock.accept()
try:
cli_sock.sendall(b'''HTTP/1.1 302 Moved Temporarily\r\n'''
b'''Content-Type: text/html\r\n'''
b'''Content-Length: 0\r\n'''
b'''Connection: close\r\n'''
b'''Location: https://www.microsoft.com/\r\n\r\n''')
except Exception: # 防止客户端提前关闭连接抛异常
pass
def wait_second():
time.sleep(1) # 等待1秒钟,确保数据发送完毕
cli_sock.close()
threading.Thread(target=wait_second).start()
if __name__ == '__main__':
main()
改完测试,发现在Linux下仍旧被TCP Reset了(但在Windows下成功跳转了)。什么原因?通过抓包,我们看到对TCP window size的修改并没有生效,window size依旧很大。在查阅了Linux man page后我们看到关于SO_RCVBUF有这么一段话:
The minimum (doubled) value for this option is 256.
这也就意味着即使我们通过setsockopt()将SO_RCVBUF设置为1,Linux内核也会将其作为256处理(Windows却没有这个限制)。而Linux man page中也对SO_RCVBUFFORCE做了说明:只能突破最大值的限制(but the rmem_max limit can be overridden),但不能突破最小值的限制。而256字节基本就可以容纳整个HTTP Request。看来通过setsockopt()行不通(不管SO_RCVBUF还是SO_RCVBUFFORCE都行不通),Linux下我们得找别的方法。
讲到这里,我们很自然地又想到了Geneva:上述Geneva的策略2中服务器规则正是利用了TCP window size做到的四字节分割(设置window size为4)。这样,就绕过了setsockopt()的限制,直接对TCP数据包进行修改了。
在我们把四字节分割法部署到服务器运行Geneva后,再结合上述Python小程序,经过测试我们发现已经成功绕过了TCP Reset,浏览器跳转到了微软网站。我们终于成功了!
然而,在浏览器第二次访问服务器时发现依然被TCP Reset了。不过,这已经影响不到301跳转(上述Python小程序还是302跳转,需要301的同学自行修改)了,301跳转的话浏览器已经被重定向到新的网站了,不会再次访问这个服务器(需要保证新旧网站不能使用相同IP),但这并不妨碍我们继续探究一下为什么第二次访问会被TCP Reset:通过抓包我们看到,第一次访问时浏览器虽然在第一个附带用户数据的数据包中只发送了4个字节,但后续会将剩余的整个HTTP Request通过一个数据包发送到服务器导致TCP Reset。而墙是有审查残留的,一段时间(几分钟)内不管是否出现关键字,对源IP和目标IP之间的TCP连接会进行无差别的Reset。所以在之后的这段审查残留时间内,只要TCP连接建立就会被Reset,抢答模式无法起到作用。
知道了原因我们就能采取对策了,我们知道客户端是因为收到了服务器确认数据包中的TCP window size很大,所以才能一次性把剩余的Request发送完毕,所以需要对后续的TCP window size做同样的修改,保证客户端看到的window size一直处于比较小的水平:通过对TCP协议的了解,我们知道连接建立时的window size是通过SYN+ACK包确定的,而后续的window size是通过ACK或PSH+ACK包确定的。所以,我们对规则2做少许的修改就能做到对后续window size的修改:
[TCP:flags:A]-tamper{TCP:window:replace:1}-|
[TCP:flags:PA]-tamper{TCP:window:replace:1}-|
在服务器上我们同时运行规则2和上述修改后的2条规则(需要开3个Geneva进程,注意第2、第3个进程需要在命令行中指定--in-queue-num和--out-queue-num避免和第1个冲突),我们终于能稳定地运行上述抢答模式,再也不会被TCP Reset了。
实际上我们可以将3条规则中的window size都设置得更小一些,甚至设置为0,避免客户端发送任何数据(实际上由于window size探测机制的原因,客户端仍旧会以极慢的速度一个字节一个字节地发送数据,不过不影响我们的抢答模式):
[TCP:flags:SA]-tamper{TCP:window:replace:0}-|
[TCP:flags:A]-tamper{TCP:window:replace:0}-|
[TCP:flags:PA]-tamper{TCP:window:replace:0}-|
至此,HTTP的抢答模式就基本完成了。至于海外301跳转的那些服务可以同时服务于多个网站,原理也很简单:它们的名称虽然都是301跳转,但实际上并不一定必须使用301跳转——以上Python小程序可以修改为通过HTTP 200返回一个正常的HTML页面,其中嵌入一个JavaScript,在JavaScript中就能判断浏览器的网址进行条件跳转了。至于跳转规则,那大家就能在JavaScript中充分发挥自己的想象了。另外,由于Geneva和上述小程序都是用Python编写的(甚至都没有使用asyncio),性能会比较差一些。Geneva会自己添加iptables的NFQUEUE规则,不过规则太过于宽松,导致不需要处理的数据包也会经过Geneva,并且会有规则覆盖的问题。所以大家需要在启动Geneva后手动删除这些规则,自行添加更精确的规则(3条iptables规则需要分别设置成只处理OUTPUT链中TCP 80端口的SYN+ACK、ACK和PSH+ACK,避免条件重叠)。另外需要注意的是Geneva区分客户端模式还是服务器模式,在服务器上运行的话需要加上--server-side参数。不过经过我的测试,即使使用精确的iptables规则也差不多只能利用20Mbps左右的带宽。如果希望有更高的性能,可以使用C/C++(结合libev,或asio,或直接epoll;或者使用golang、rust等)结合libnetfilter_queue,利用iptables的NFQUEUE来完成,可以跑满千兆带宽。其实Geneva的底层用的也是libnetfilter_queue和NFQUEUE。由于本系列只做概念验证,而且因为篇幅的限制(本文已经很长了),在此就不展开C/C++的实现了,感兴趣的同学可以和我联系,如果感兴趣的同学比较多的话我就再新开一个系列讲一下这方面的内容。另外需要注意的是,Geneva的编译环境为Python 3.6,使用Debian 10自带的Python 3.8/3.9会出现各种莫名其妙的问题,建议大家还是从Python官网下载Python 3.6的源码进行编译使用Geneva。嫌麻烦的同学如果不想折腾Geneva也可以将服务器换成Windows系统,可以直接使用上述Python小程序完成抢答模式。
在解决了HTTP的TCP Reset问题后,我们还需要解决HTTPS的TCP Reset。而HTTPS由于需要完成TLS握手才能发送HTTP Response,所以抢答模式似乎无法应用于HTTPS.
我们知道,HTTPS是需要客户端和服务器之间完成TLS握手后才能收发HTTP Request和Response。然而,墙是在TLS握手时通过SNI中的域名信息进行了TCP Reset,或通过ESNI头进行TCP阻断,这时候还没有到能发送HTTP Request或Response的这个阶段,所以HTTP Response抢答模式无法应用于HTTPS。那么,我们该怎么办呢?
让我们回到TCP Reset本身——既然是TCP Reset,那么它只会对TCP协议生效。如果有一个应用层协议,其底层不是TCP呢?相信聪明的同学已经想到了,那就是HTTP 3.0(简称HTTP/3或h3)。H3的底层协议是QUIC,而QUIC是基于UDP而非TCP的。经过我的测试,发现墙现在无法识别QUIC协议,不管QUIC协议中出现任何敏感词都能无障碍过墙。这也是为什么有些网站(如v2ex)在解决了DNS污染(比如客户端主动加hosts)后,并且连接过一次(首次还是需要科学上网,原因之后会讲)后,就能关闭科学上网访问了。也就是说,使用了H3后,我们甚至不需要进行301跳转,直接就能无障碍访问服务器了(但仍建议使用301跳转,否则可能会使封锁升级,如DNS污染)。虽然H3现在仍旧处于草案阶段,但各大浏览器都已经进行了支持,而其中Google Chrome对H3的支持是最好的。
那么,如何在服务器上部署并开启H3呢?由于H3现在仍是草案阶段,所以Nginx的正式版并不支持H3,需要更换为Nginx-QUIC来支持H3。编译使用Nginx-QUIC也可以参考这篇文章。另外,Cloudflare也已经支持了H3,可以自行开启(在“网络”设置中打开“HTTP/3(使用 QUIC)”)。在Cloudflare中开启H3后,Cloudflare和服务器的通讯仍旧可以使用HTTP/2(简称h2)或HTTP/1.1,并不需要服务器支持H3,而是由Cloudflare进行协议转换。
H3主要是依赖Alt-Svc这个HTTP头来进行协议选则的。比如我们可以添加HTTP头:
Alt-Svc: h3=":443"; ma=86400, h3-29=":443"; ma=86400, h3-28=":443"; ma=86400, h3-27=":443"; ma=86400
指出服务器支持H3,H3的UDP端口为443,有效期(过了有效期后浏览器又会重新使用H2或HTTP/1.1进行访问)为1天(86400秒),支持最新的H3草案以及27、28、29草案。另外,我们也可以灵活地修改Alt-Svc——比如可以在“:443”之前添加IP或域名,做到HTTP和HTTPS使用不用的IP或域名,方便我们在自己的服务器上部署HTTP抢答模式,又能使用Cloudflare的H3协议转换,或者使用不同的域名从而在原域名被DNS污染的情况下老用户(没有过有效期86400秒的)依然可以通过H3访问服务器(因为H3是另一个域名,而不是被DNS污染的那个域名。或者直接使用IP,从根本上杜绝了DNS污染,只不过之后有可能遭到IP封锁)。另外,有效时间也可以进行适当延长(比如从1天延长到1个月或更长时间),避免客户端尝试H2或HTTP/1.1并且延长老用户的过期时间。我们可以在还没遇到HTTPS的TCP Reset时就开启H3,这样即使之后遭遇了HTTPS的TCP Reset,曾经访问过网站的老用户在H3有效期内也能继续访问网站。而且我们也不必担心UDP数据包被ISP丢弃(俗称UDP被QoS)的问题,因为浏览器在H3连接失败的时候会快速回退到H2和HTTP/1.1。
然而,H3是一个Alternative服务。首次访问服务器时,浏览器并不会主动使用H3,还是会优先使用H2或HTTP/1.1。当获取到Alt-Svc头后,浏览器才会在之后的访问中优先使用H3。这也是为什么有些网站(如v2ex)需要在科学上网的情况下访问过一次后才能关闭科学上网进行访问(当然,DNS污染首先还是需要用户自行修改hosts解决)。那么,我们如何让用户全程不使用科学上网的情况下访问服务器呢?
首先想到的是通过上面提到的HTTP抢答模式提供Alt-Svc头,不过可惜的是现在的主流浏览器会忽略HTTP中的Alt-Svc头,只接受HTTPS中的Alt-Svc头。而如果HTTPS本来就已经被TCP Reset的话,浏览器就无法获取Alt-Svc头了。那么,那些提供HTTPS的301海外跳转服务是怎么做的呢?
在调查和尝试了几个支持HTTPS的301海外跳转服务后,我们发现,它们根本就没有解决HTTPS的TCP Reset问题,HTTPS依然被TCP Reset了,而它们宣称支持HTTPS中301跳转的做法就是在HTTP抢答模式下加上普通的TLS服务。因为大部分网站遭遇的只是HTTP中的TCP Reset而HTTPS并不会被TCP Reset,所以只需要解决HTTP的301跳转,再加上普通的HTTPS,表面上就能同时做到HTTP和HTTPS的301跳转。而且在调查过程中我们还发现有个跳转服务主页的HTTPS也被TCP Reset了,而他们自己却对此毫无办法。那么,对于新用户访问HTTPS的TCP Reset,我们也只能止步于此,束手无策了吗?那也未必。
其实,从本系列一开始,我们就假设301跳转服务器是在国外。如果使用的是国内服务器,那么就能避免墙的识别了(因为不过墙)。但使用国内服务器(似乎)有个绕不过去的坎:备案系统——使用HTTP会提示域名没有备案,使用默认端口443的HTTPS同样会有TCP Reset。我们又该怎么办?其实,备案系统其实就是一个简化版的墙,没有TCP流量重组的功能,使用上面提到的抢答模式同样也能绕过备案系统。而且正是因为备案系统没有TCP流量重组的功能,我们甚至可以在TCP模式的HTTP和HTTPS中设置TCP window size(比如Linux上可以使用Geneva;Windows上可以自行编写一个反向代理,在其中设置SO_RCVBUF为1,两者的用法在上面都已进行说明,在此不再重复),从而可以直接通过HTTP和HTTPS绕过备案系统而无需使用301跳转(因为备案系统没有TCP流量重组功能,所以只需要在连接初始时设置个较小的TCP window size,之后恢复正常即可。这也是很多国内免备案服务器的原理和使用的方案)。不过,绕过备案系统展示网页有一定的风险,301跳转风险会小一些,希望大家还是要权衡好利弊。
在讨论好HTTPS中防TCP Reset的方案后,最后让我们来聊一聊DNS污染。
其实,在撰写本文之前,我曾去尝试过几个声称可以解决域名污染的301海外跳转的服务,但无一例外都失败了,都无法解决DNS污染。然后我也去咨询了提供了这些服务的人,他们的说法大致分为两种:
- 需要将被DNS污染的域名的NS记录指向国内的DNS服务(如DNSPod、阿里云等),然后需要等一段时间,运气好的话过一段时间就会解封了(对于这种说法,我也曾经亲自验证过,将一个被DNS污染的域名的NS记录转移回国内,等了几个月,依然被污染)。
- 域名污染指的是域名被关键字Reset,而不是DNS污染(这个说法和大多数人理解的不同,将域名污染解释为了TCP Reset,和DNS污染分为了两个概念),他的服务只能解决域名污染,不能解决DNS污染。
那么,对于DNS污染,我们只能束手无策,或只能碰运气转移回国内了吗?那也未必。不过,由于解决DNS污染所需要的成本较高,所以这也是为什么之前H3虽然能让用户在原有域名下继续访问,我仍旧建议使用301跳转的原因。否则封锁升级为DNS污染后连301跳转都会变得比较困难了。
讲到这里,细心的同学应该已经发现,其实在刚才H3的使用方法中,已经介绍了如何使老用户在DNS污染的情况下继续进行访问的方法了。这是解决DNS污染部分问题的方法之一。那么,还有没有别的方法也能解决部分问题呢?其实,在H3的方案中,我们主要利用了浏览器的Cache中记录了H3的服务信息,来让老用户通过不同的域名或IP进行访问的。那么,浏览器的Cache中除了能保存H3的信息外,也是可以保存其他内容的。讲到这里,聪明的同学应该已经想到了。没错,就是Cache-Control(或使用Expires也有相同的效果)。通过这个HTTP头,我们可以将一个页面的过期时间设置成很长,在过期之前,浏览器并不会发起HTTP请求,甚至没有网络的离线情况下都能访问(使用F5刷新除外,这时候浏览器会忽略过期时间从而发起HTTP请求)。在这个页面中,我们可以引用别的域名下的JavaScript脚本文件,在JavaScript而非HTML中渲染整个网页。这样,老用户同样可以在DNS污染的情况下继续访问我们的服务器。不过,这种做法对SEO不是很友好,但我们可以使用HTML和JavaScript同时渲染的方法让搜索引擎可以进行索引——HTML中仍旧是正常内容给搜索引擎进行索引,而浏览器会加载JavaScript,使用JavaScript重新渲染一遍网页,避免Cache没有过期而呈现老页面的问题。老用户的问题可以解决,但新用户怎么办呢?或者我们有没有办法从根本上来解决DNS污染呢?而且听说现在有一些价格昂贵的污染清洗服务,它们真的能从根本上解决DNS污染吗?它们是怎么做的呢?
如果我们想从根本上解决问题,首先我们还需要了解整个DNS系统是怎么工作的:
- DNS服务器分为递归查询服务器、DNS代理和权威服务器(称为ADNS)。我们把递归查询服务器和DNS代理统称为LDNS。
- 普通用户上网所使用的一般是ISP提供的LDNS,它会负责向ADNS查询真实的A(和AAAA以及其它)记录。
- ADNS即是域名的NS记录所指向的服务器。
我们知道,DNS污染是墙在海外ADNS返回正确的结果之前进行了抢答,返回了错误的结果。这样,在国内LDNS向海外ADNS查询的时候,同样会受到DNS污染,从而返回给普通用户错误的结果。那么,我们有没有办法劫持ISP的LDNS,从而让其返回我们想要的IP而不是墙返回的错误IP呢?这样,虽然DNS污染仍旧存在,但普通用户却得到了正确的IP,从而可以正常访问我们的服务器了。
讲到这里,就不得不提到2008年曾经轰动全球的DNS投毒攻击案了。在这篇文章中,Kaminsky可以修改任意LDNS中缓存的A(或AAAA以及其它)记录,虽然在经过了那次事件后这个漏洞更难被利用了,但终究无法完全修复,我们仍旧可以利用其中的原理劫持ISP的LDNS(能猜中源端口和QID就能进行劫持),将被污染域名的IP换成自己想要的IP。而且由于墙污染的TTL较小,我们也能更快地利用这个漏洞而不需要每次等待1天的时间。所以短则几天,慢则几个星期就能劫持成功。这也是现在有些价格不菲的污染清洗服务所采用的方案之一。当然,某些攻击团队也同样在利用这个漏洞就行DNS劫持,虽然导致的结果是LDNS被劫持而非墙的DNS污染,但对于普通用户所造成的结果是一致的——网站无法访问。不过,要实施这种DNS劫持需要源IP欺骗,现在能进行源IP欺骗的服务器已经越来越少了。那么我们还有没有别的方法无需源IP欺骗来劫持LDNS呢?
既然大家已经看了上面的文章,那么让我们来重新细致地梳理一下整个DNS查询过程。以浏览器访问 https://www.youtube.com/ 为例:
- 操作系统向ISP的LDNS发起请求 www.youtube.com 的A(以及AAAA)记录。
- LDNS查询缓存中有没有 www.youtube.com 的A(或AAAA)记录,如有则返回给客户端,如没有则执行第3条。
- LDNS查询(可从缓存中查询)DNS根服务器(当前为13个)的A(或AAAA)记录。
- LDNS向根服务器(或从缓存中)查询 .com 的ADNS。
- LDNS向 .com 的ADNS发起查询 youtube.com 的ADNS(即 youtube.com 的NS记录)。
- LDNS向 youtube.com 的ADNS发起查询 www.youtube.com 的A(或AAAA)记录。之后返回给客户端。
我们知道, youtube.com 是个被DNS污染的域名,所以第5和第6步会受到墙的DNS污染,而前4步不会。第6步我们也很熟悉了,国内IP向国外IP发起查询请求时墙就会抢答 www.youtube.com 的错误A(或AAAA)记录。而第5步中,由于LDNS在国内,查询到 youtube.com 的NS记录同样会受到污染。我们同样知道,墙的DNS污染虽然成功概率接近100%,但仍有很小的概率会污染失败。那么我们能不能不停地向LDNS请求 www.youtube.com 的A(或AAAA)记录,在墙污染失败的时候,LDNS就能刷新到正确的IP地址了呢?可惜的是,LDNS是有缓存的,在缓存有效期内,不会再次向ADNS发起请求。即使在缓存失效后偶尔会由于污染失败得到了正确的IP地址,但在缓存再次失效后由于污染再次回到了错误的IP地址。所以被污染的概率仍旧接近100%。墙看上去似乎无懈可击,我们该怎么办呢?
让我们重新回到第5条,使用国内IP向 .com 的ADNS请求 youtube.com 的NS记录。以Linux为例:
dig ns youtube.com @e.gtld-servers.net
(e.gtld-servers.net为 .com 的其中一个ADNS)
我们看到墙返回了污染的结果, youtube.com 被污染的NS是……咦?不对!墙竟然返回的是A(或AAAA)记录,而不是我们查询的NS记录!而且墙的污染是有很小的概率会失败的!相信聪明的同学已经想到了——由于墙返回的是不是NS记录,所以LDNS没有获取到 youtube.com 的NS记录,自然无法将 youtube.com 的NS记录存入缓存中。所以,在下次客户端请求 youtube.com 的NS记录时,LDNS会再次向 .com 的ADNS请求 youtube.com 的NS记录而不是从缓存中获取。既然不存在缓存,我们就能一直向LDNS发起请求,而LDNS就会一直向ADNS发起请求,直到墙的污染失败出现,LDNS终于获得了正确的NS记录。而由于NS记录本身是带有TTL的,所以会被存入LDNS的缓存之中,在缓存过期之前不会再受到墙的污染。而我们可以将NS记录的TTL设置得非常长,从而可以在很长得时间内让墙得污染无法生效。而在TTL过期之后,我们可以利用同样的方法再次让LDNS获得正确的NS记录。
在解决了第5条中的污染后,我们还需要解决第6条中的污染。而第6条中墙返回的确实是查询的A(或AAAA)记录,会被存入LDNS缓存,也就无法利用上述方法了。我们该怎么办呢?相信聪明的同学也已经想到了。没错,就是将NS记录转移回国内,这样DNS请求就不会过墙,自然就不会受到污染了。可是,不对呀?刚才不是讲过我也曾经亲自验证过,将一个被DNS污染的域名的NS记录转移回国内,等了几个月,依然被污染么?那是因为之前的测试只是将NS记录指向了国内服务器,我们并没有大量地发送NS查询请求到LDNS,所以LDNS并没有获得正确的NS记录,所以污染仍旧存在。而且,ISP的LDNS是分运营商并且分区域的。只将一个LDNS中的NS刷新到正确结果只能解决一个运营商的一小片区域中的污染,如果想要在全国范围内解决污染,需要使用大量的IP地址(因为很多ISP的LDNS限制了查询请求的发起IP只能是本地宽带用户),不停地对大量的LDNS查询NS记录,直到全国大部分地区的LDNS都获取到了正确的NS记录,才能在大范围内解决DNS污染。而且即使LDNS获取到了正确的NS记录,查询仍然要继续,因为缓存是有过期时间的。而这,也是现在很多昂贵的污染清洗服务所采用的方案之一。

